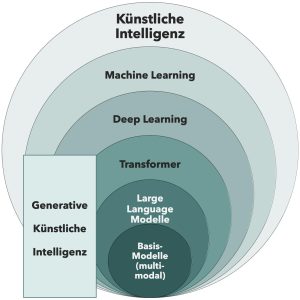
Bild 1: Die „KI Zwiebel“ stellt die verschiedenen Schichten Künstlicher Intelligenz dar. Von Künstlicher Intelligenz über Machine Learning und Deep Learning bis hin zu multimodalen Foundation-Modellen.
KI ist längst kein Zukunftsprojekt mehr: Mit maschinellem Lernen und Deep Learning verbessern mittelständische Unternehmen in der DACH-Region Prozesse, senken Kosten und schonen die Umwelt – oft mit klassischen Methoden und ohne große Sprachmodelle. Drei Beispiele aus der Praxis zeigen, wie der Einstieg gelingt.
1. KI im Mittelstand
Rolle der KI für DACH-Unternehmen
Der Mittelstand steht heute vor der doppelten Herausforderung, effizienter und zugleich nachhaltiger zu produzieren. Wettbewerbsfähigkeit hängt zunehmend davon ab, wie flexibel Unternehmen auf volatile Märkte, steigende Energiekosten und neue regulatorische Anforderungen reagieren können. Künstliche Intelligenz eröffnet hier praxisnahe Lösungen – nicht nur in globalen Konzernen, sondern gerade auch in mittelständischen Strukturen.
Dabei lohnt es sich, genauer hinzuschauen: Was unter „KI“ verstanden wird, reicht von etablierten Machine-Learning-Verfahren wie Entscheidungsbäumen bis hin zu komplexen Deep-Learning-Architekturen. In dieser Artikelserie werden die verschiedenen Schichten der KI vorgestellt – jeweils illustriert durch ein konkretes Anwendungsbeispiel aus der DACH-Region.
Schichten der KI als roter Faden
Um die Vielfalt der Künstlichen Intelligenz greifbar zu machen, lohnt sich ein Blick auf ihre Schichten. An der weitesten Basis steht der allgemeine Begriff „KI“. Darin eingebettet finden sich klassische Machine-Learning-Methoden, die seit Jahren erfolgreich in der Industrie eingesetzt werden – etwa Entscheidungsbäume zur Mustererkennung. Eine Ebene tiefer eröffnet Deep Learning zusätzliche Möglichkeiten, vor allem in der Bild- und Objekterkennung. Darauf aufbauend stehen moderne Transformer-Architekturen, die wiederum die Grundlage für Large Language Modelle (LLMs) und multimodale Basismodelle bilden.
In diesem Artikel werden die verschiedenen Schichten als roter Faden genutzt. Statt den aktuellen Hype um generative KI und LLMs in den Mittelpunkt zu stellen, geht es darum, wie Unternehmen mit erprobten Methoden ganz konkrete Mehrwerte schaffen.
Einstiegshürden sinken, Anwendungsfälle entstehen durch verschiedene Branchen
Noch vor wenigen Jahren galt der Einsatz von KI in mittelständischen Unternehmen als aufwendig und teuer. Heute sind die Hürden deutlich niedriger: Cloud-Dienste, Open-Source-Modelle und spezialisierte Hardware erleichtern den Zugang. Hinzu kommen Partnernetzwerke, Hochschulkooperationen und Förderprogramme, die gerade kleinen und mittleren Unternehmen den Einstieg erleichtern.
Die Praxis zeigt: KI-Anwendungen entstehen inzwischen quer durch verschiedene Branchen. Was in einem Käsemixer funktioniert, lässt sich in adaptierter Form auch bei der Getränkeabfüllung oder bei der Kartoffelernte einsetzen. Die Beispiele verdeutlichen, dass es nicht um exotische Forschung, sondern um praxisnahe Lösungen geht, welche die Effizienz steigern, Kosten senken und gleichzeitig nachhaltigeres Wirtschaften ermöglichen.
2. Basiswissen: Die KI-Zwiebel
Künstliche Intelligenz ist kein monolithisches System, sondern ein mehrschichtiges Gefüge aus Methoden, Architekturen und Anwendungen. Um den Überblick zu behalten, hilft das Konzept der „KI-Zwiebel“: Sie zeigt, wie sich die verschiedenen Ebenen der Intelligenzsysteme ineinander verschachteln – von klassischen Machine-Learning-Verfahren bis hin zu multimodalen Basismodellen.
Überblick über die Schichten von KI – von Machine Learning bis zu multimodalen Basismodellen
An der äußeren Schicht steht der weite Begriff „Künstliche Intelligenz“. Er umfasst alles, was maschinelle Systeme dazu befähigt, Aufgaben zu lösen, die typischerweise menschliche Intelligenz erfordern – also Wahrnehmen, Lernen, Entscheiden und Handeln.
Eine Ebene darunter folgt das „Machine Learning“ (ML), das es Systemen ermöglicht, aus Daten zu lernen, anstatt explizit programmiert zu werden. Es bildet das Fundament heutiger KI-Anwendungen – von der Nachfrageprognose bis zur Qualitätskontrolle.
Noch tiefer in der Zwiebel liegt das „Deep Learning“ (DL). Hier arbeiten künstliche neuronale Netze mit vielen Schichten, die komplexe Muster in Bildern, Tönen oder Texten erkennen. Diese Methoden haben in den letzten Jahren vor allem durch Fortschritte in der Hardware und die Verfügbarkeit großer Datenmengen enorme Schubkraft erhalten.
Darauf bauen Transformer-Modelle auf – Architekturen, die erstmals eine effiziente Verarbeitung langer Datenkontexte ermöglichten. Sie sind die Grundlage heutiger Large Language Models (LLMs) wie ChatGPT oder Claude. Die innerste Schicht schließlich bilden die multimodalen Basismodelle, die nicht nur Sprache, sondern auch Bild, Audio, Präsentationen und Sensorik verarbeiten können.
Die Grafik der „KI-Zwiebel“ verdeutlicht: Jede Schicht baut auf der vorherigen auf – aber nicht jedes Unternehmen muss bis ins Zentrum vordringen, um echten Nutzen zu erzielen. Im Gegenteil: Viele erfolgreiche Anwendungen im Mittelstand entstehen auf den äußeren, bereits seit vielen Jahren bewährten Ebenen.
Warum das Verständnis der Schichten wichtig ist
Wer die Schichten versteht, kann Technologie gezielter einsetzen. Denn zwischen klassischen ML-Modellen und modernen LLMs liegen Welten – in Datenbedarf, Bedarf an Rechenleistung und Implementierungsaufwand. Für viele mittelständische Unternehmen lohnt es sich daher, zunächst auf bewährte ML-Verfahren zu setzen, die sich mit überschaubarem Aufwand trainieren und warten lassen. Gerade diese Perspektive schützt vor Fehlinvestitionen: Nicht jede Aufgabe braucht generative KI. Häufig genügt ein präzise trainiertes Modell, welches eine klar umrissene Fragestellung beantwortet – etwa die Vorhersage von Wartungsintervallen für Weichen eines Bergbahnbetreibers oder die Erkennung von Qualitätsabweichungen in der Linsenproduktion.
Typische Missverständnisse und Abgrenzungen
Im öffentlichen Diskurs werden KI, Machine Learning und Deep Learning oft gleichgesetzt. Das führt zu Missverständnissen, welche den Einstieg erschweren. Während KI den übergeordneten Begriff bildet, ist Machine Learning ein Teilbereich davon – und Deep Learning wiederum ein spezielles Verfahren innerhalb des ML.
Diese begriffliche Trennung ist nicht nur akademisch, sondern auch praktisch relevant: Sie hilft Unternehmen, realistische Ziele zu definieren und die passende Technologie auszuwählen.
3. Erste Schicht: Klassische Machine-Learning-Modelle
Die äußere Schicht der KI-Zwiebel steht für klassische Machine-Learning-Methoden. Sie bilden die Basis vieler industrieller Anwendungen und sind häufig der pragmatischste Einstieg in datengetriebene Optimierung.
Erklärung im klassischen Machine-Learning: Entscheidungsbäume, Predictive-Maintenance-Ansätze
Typische Verfahren sind etwa Entscheidungsbäume, Random Forests oder sog. Support-Vector-Machines (SVMs). Diese Modelle lernen aus historischen Daten, um neue Eingaben zu bewerten oder Vorhersagen zu treffen.
Ein Beispiel: Wenn ein Sensor in einer Produktionslinie regelmäßig Temperatur, Vibration und Stromverbrauch misst, kann ein ML-Modell lernen, aus diesen Mustern frühzeitig auf mögliche Störungen zu schließen. So lassen sich Wartungsarbeiten planen, bevor es zu Ausfällen kommt – ein Ansatz, der als Predictive Maintenance bekannt ist.
Der Vorteil klassischer ML-Verfahren liegt in ihrer Transparenz: Unternehmen können nachvollziehen, wie ein Modell zu seiner Entscheidung gelangt. Zudem sind die Anforderungen an Rechenleistung und Datenmenge vergleichsweise gering. In einigen Fällen muss bei cleverem Setup der Logik nicht einmal zusätzliche Server-Hardware angeschafft werden. Für den Mittelstand bedeutet das: Mit überschaubaren Investitionen lassen sich konkrete Mehrwerte erzielen.
Use Case: Frühwarnsystem in der milchverarbeitenden Industrie
In einer Schmelzkäselinie einer Molkerei stand die Produktion immer wieder vor demselben Problem: Zwischen Mischer und Schmelzofen konnte es zu einer Verstopfung der Leitung kommen – intern nur das „Pumpenproblem“ genannt. Eine solche Verstopfung bedeutete jedes Mal einen vollständigen Produktionsstopp, bis zu sechs Stunden Reinigungszeit und erhebliche Materialverluste. Bisher verließ man sich auf die Erfahrung eines langjährigen Mitarbeiters: „Helmut“ am Mixer hörte und fühlte, wann die Fließfähigkeit der Käsemasse nachließ. Dann fügte er etwas Wasser hinzu – und die Produktion lief weiter. Doch Helmut hat auch einmal Urlaub. Und irgendwann geht er in Rente.
Um dieses Wissen zu digitalisieren, wurde ein Machine-Learning-Modell entwickelt, das „Helmuts Job“ übernimmt – ein dreischichtiger Entscheidungsbaum, der auf historischen Prozessdaten basiert. Ziel war es, potenzielle Verstopfungen frühzeitig zu erkennen und so rechtzeitig eingreifen zu können, bevor die Leitung blockiert. Dabei wurden verschiedene Einflussfaktoren untersucht: die Rezeptur, das Alter der Rohmaterialien, die Intensität der Mischung sowie zeitliche Abläufe im Prozess – etwa die Zeitspanne zwischen Auspacken, Mischen und Probenentnahme. Schnell zeigte sich: Die Menge des zugegebenen Wassers hat den größten Einfluss und erklärt rund 61 Prozent der Varianz im Modell.
Das Ergebnis ist ein sog. „Soft Sensor“ mit Ampelsystem, welcher die Wahrscheinlichkeit einer Verstopfung visuell darstellt. Die Bedienerinnen und Bediener können dadurch eingreifen, bevor es kritisch wird – ein Beispiel für vorausschauende Wartung im besten Sinne. Das Besondere an dieser Lösung: Sie ist einfach, transparent und erklärbar. Kein komplexes Deep Learning, keine Cloudabhängigkeit – sondern ein klar nachvollziehbarer Entscheidungsbaum, der von den Mitarbeitenden verstanden und akzeptiert wird.
So zeigt der Use Case eindrucksvoll, dass einfache Modelle oft die robustesten Lösungen liefern können – ganz ohne den aktuellen Hype um Large Language Modelle.
4. Fazit und Ausblick auf das nächste Teilgebiet
Künstliche Intelligenz ist längst kein Zukunftsversprechen mehr, sondern Teil des industriellen Alltags. Besonders klassische Machine-Learning-Verfahren bieten mittelständischen Unternehmen einen realistischen, wirtschaftlich sinnvollen Einstieg in datengetriebene Optimierung. Sie machen Prozesse effizienter, reduzieren Ressourcenverbrauch und schaffen Erfahrungswissen, welches den Weg für komplexere Anwendungen ebnet.
Im nächsten Teil dieser Reihe geht es eine Schicht tiefer in der KI-Zwiebel: Dort, wo neuronale Netze beginnen, visuelle Daten zu verstehen – und Deep Learning in der Produktion völlig neue Möglichkeiten eröffnet.

Autor
Autor
Prof. Dr. rer. nat. Alexander Maximilian Lutz

